
Index
前回の記事では、シナリオ設計までの流れを紹介しました。

今回はその続きとして、画像生成をどう詰めたかにフォーカスします。
結論から言うと、
動画AI以前に、画像生成の設計が9割を決めていました。
特に今回の制作では、Nanobananaを使った画像生成が、「ただの一枚絵」ではなく“後工程に耐える素材”として機能するかが最大のテーマでした。


動画のクオリティは、ほぼ画像生成で決まります
まず全体像|画像生成はこういうフローで進めた
今回の画像生成は、以下の流れで行っています。
① キャラクター生成(基準となる1枚を作る)
② ポーズ生成(ガチャ前提)
③ 画像生成(Nanobananaで差分を展開)
④ 背景生成と合成
⑤ Photoshopで整合性を取る
⑥ スタイル変換(水墨画)
ここで重要なのは、
すべてをAIで一発生成しようとしないことでした。
Nanobananaが“これまでのAIと違った”点
Nanobananaを使って、これまでの画像生成AIと明確に違うと感じた点があります。
- 同一キャラを角度違い・ポーズ違いで出し続けられる
- 一枚の参照画像から、別シーンに再登場させられる
- 「ここだけ直したい」が通る(部分修正耐性が高い)




差分を作ることで物語が進んでいく・・・これは、「一枚きれいな絵」を作るAIではなく、“素材を組み立てるAI”に近い感覚でした。

キャラの一貫性が、ここまで保てるのは衝撃でした
画像生成|ガチャ前提で“使える候補”を集める
優秀なNanobananaでも画像生成にガチャ性は確実に存在します。
- 同じプロンプトでも微妙にズレる
- 表情が意図せずコメディ寄りになる
刀や手の位置が怪しくなる

そのため、
「正解を1枚当てる」のではなく「使える候補を揃える」
という考え方に切り替えました。
③ スタイル変換|水墨画で“世界観”を揃える
本作では、日本的美意識を強めるために水墨画スタイルへの変換を行っています。

これにより、シーンが変わっても絵としての世界観が分断されにくくなりました。
背景生成と合成|一発生成を捨てる判断
Nanobananaでも、キャラ+複雑な背景を同時に指定すると破綻率が一気に上がります。
特に難しかったのが、
- 路地での戦闘
- 屋上での戦闘
- 炎+キャラ+奥行き



そこで、
- キャラ
- 背景
- エフェクト
を完全に分離生成し、Photoshopで合成する方法を採用しました。



これは路地裏を先に生成し、そこに人物を配置するようにしています。
人物も先にポーズを決めておくとよりスムーズに自分の想像に当てはまったシーンが生成できますよ。
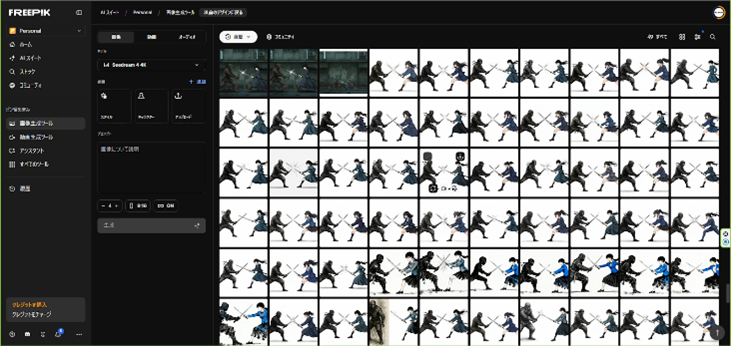
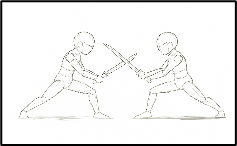
ポーズ生成|ガチャを前提に“当たりを拾う”
今回もっとも試行回数が多かった工程がポーズ指定でした。
- 試行回数:100〜300枚
- 3Dデッサンでリファレンス作成
- それでも完全再現は難しい

ここでは、
完璧を狙わず、8割の当たりを拾って育てるという判断が重要でした。
Photoshopでの力技修正|AIを信じきらない
最終的に、多くのシーンでAIの解釈に任せず手で直しています。

これは失敗ではなく、「AI生成を素材として扱う」という前提に立った結果です。

ここはもう、割り切りが必要でした
まとめ|次は動画編です
今回はNanobananaを使った画像生成の工程を整理しました。
- Nanobananaは設計向き
- ガチャ性は前提、拾って育てる
- 背景・ポーズ・エフェクトは分けると安定
- 最後はPhotoshopで締める
次回は、この画像をどう動画にしたのか。
うまくいった点も、盛大に崩れた点も含めて、動画編としてまとめます。
次はいよいよ動画化の話をします